
在AI大模型飞速迭代的今天,“架构决定能力边界”这句话愈发贴切。我们常常听说MoE和Dense这两种核心架构,也频繁使用Codex、Cursor、Claude等AI工具,但很少有人将二者关联起来——其实,这些工具的性能、速度和适用场景,早已被其背后的架构选择所决定。
今天,我们就先理清MoE与Dense的核心区别,再拆解三大热门AI工具的架构选型逻辑,帮你搞懂“为什么有的工具快如闪电,有的工具稳如磐石”,也让你在选择AI工具时,能从底层逻辑上做出更合适的判断。
先搞懂基础:MoE与Dense,到底差在哪?
MoE(Mixture-of-Experts,混合专家)和Dense(稠密模型),是目前大模型最主流的两种底层架构,核心差异在于“参数是否全量激活”——这一个区别,直接决定了模型的速度、成本和稳定性。
1. Dense(稠密模型):全能通才,稳字当头
Dense模型的核心逻辑很简单:每次计算都动用全部参数。就像一个全能通才,不管遇到简单的问题(比如“写一行打印代码”)还是复杂的任务(比如“分析一篇万字报告”),都会调动自己所有的知识储备去解决。
它的优势很突出:结构简单、训练稳定,输出的内容连贯性极强,因为所有参数协同工作,不会出现“风格断层”;但缺点也很明显——成本高、效率低,模型规模越大,训练和推理的算力、显存需求就呈指数级增长,简单任务也会浪费大量资源。
典型代表:早期BERT、Llama 1/2、GPT-3,以及我们接下来要提到的Claude全系列。
2. MoE(混合专家模型):专业分工,快人一步
MoE模型则走了“专业化分工”的路线:它由多个“专家模块”和一个“门控网络”组成。门控网络就像分诊台,会根据输入的内容,筛选出1~2个最相关的专家模块来处理,其余专家则处于“休眠”状态,不参与计算。
这种设计的优势堪称“降维打击”:总参数量可以轻松做到万亿级(容量超大),但计算量只相当于1~2个专家的大小,所以推理速度快、显存占用低,适合高并发、低延迟的场景;但缺点也很突出:训练不稳定,容易出现“专家坍塌”(少数专家垄断所有任务,多数专家闲置),而且不同专家的输出风格可能不一致,会导致内容有“拼凑感”,工程实现难度也更高。
典型代表:GPT-4(推测)、Mixtral 8x7B,以及Codex、Cursor的自研模型。
一张表看懂核心差异
| 对比维度 | Dense(稠密模型) | MoE(混合专家模型) |
|---|---|---|
| 计算模式 | 全参数激活,每次都动用全部资源 | 稀疏激活,仅激活1~2个相关专家 |
| 速度与延迟 | 慢,延迟高 | 快,延迟低 |
| 输出连贯性 | 强,全局特征统一 | 较弱,可能有风格断层 |
| 工程难度 | 低,成熟稳定,易部署 | 高,需解决路由和负载均衡问题 |
| 核心优势 | 稳定、可控,适合长文档和深度推理 | 高效、低成本,适合高吞吐和专业化任务 |
重点拆解:Codex、Cursor、Claude 各自用了哪种架构?
了解了MoE和Dense的差异后,我们再看三款热门AI工具的架构选择——它们的选型,完美契合了自身的产品定位和使用场景,也能帮我们更直观地理解两种架构的实际价值。
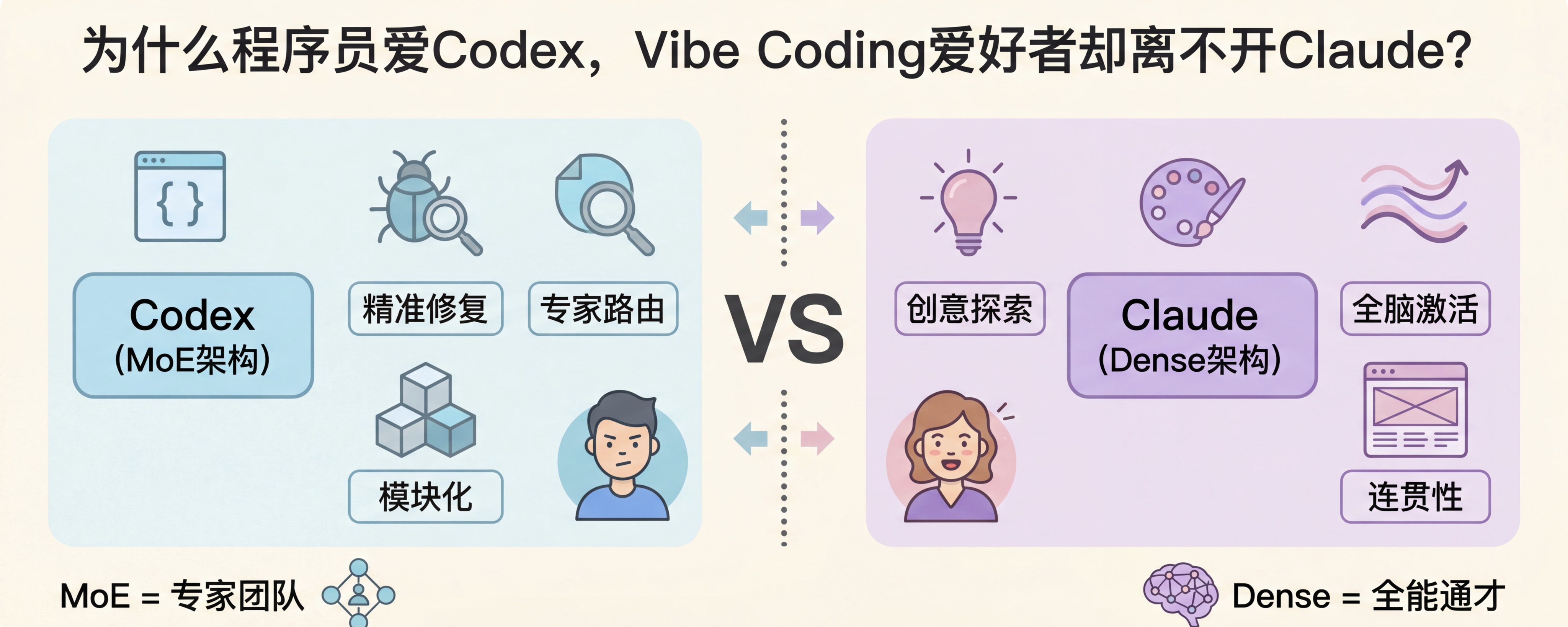
1. OpenAI Codex(GitHub Copilot 底层):MoE架构,主打“快准狠”的代码生成
作为GitHub Copilot的底层模型,Codex的核心需求很明确:低延迟、高精准,能快速响应开发者的代码生成、修复需求。而MoE架构,正是满足这一需求的最佳选择。
虽然OpenAI官方未完全公开Codex的最新架构细节,但行业技术分析和实际使用体验都一致确认:Codex采用的是MoE结构。它的总参数量庞大,能覆盖各种编程语言和场景,但每次推理只激活1~2个与“当前代码”最相关的专家模块——比如写Python代码时,激活Python专家;写前端代码时,激活前端专家。
这也是为什么GitHub Copilot能在你敲代码时“实时联想”,几乎没有延迟,同时生成的代码精准度极高——MoE的稀疏激活的特性,让它在代码生成这个“专业化场景”中,实现了速度与质量的平衡。
2. Cursor(IDE集成工具):自研Composer模型,MoE架构适配“IDE场景”
Cursor是一款深度集成IDE的AI编程工具,它的核心优势是“与编辑器无缝衔接,支持多文件理解、长上下文代码生成”,而它的自研模型Composer(包括Composer 2),官方明确表示采用的是MoE架构。
对于Cursor来说,MoE架构的优势被发挥到了极致:一方面,MoE的低延迟的特性,能让它在IDE中实时响应,不影响开发者的编码节奏;另一方面,MoE的高容量特性,能让它轻松理解多文件之间的关联(比如一个项目中的多个Python文件、配置文件),生成的代码更贴合项目实际需求。
值得一提的是,Cursor也支持切换调用GPT-4、Claude等第三方模型,这些模型会保持自身的原有架构(GPT-4推测为MoE,Claude为Dense),但Cursor的核心竞争力,依然来自其自研的MoE架构Composer模型。
3. Anthropic Claude(Opus/Sonnet/Haiku):全系列Dense架构,主打“稳与准”的深度推理
和Codex、Cursor不同,Anthropic旗下的Claude全系列(包括Opus、Sonnet、Haiku),官方和技术分析都明确表示:采用的是标准Dense Transformer架构——这和它的产品定位息息相关。
Claude的核心优势是“长上下文、深度推理、输出稳定”,主要用于长文档分析、法律文本解读、学术写作、复杂逻辑推理等场景。这些场景最核心的需求,是“输出的连贯性和准确性”,而Dense架构的优势正在于此:全参数激活让它能全局统筹上下文信息,不会出现MoE那种“专家切换导致的风格断层”,推理过程更严谨,输出的内容也更连贯。
虽然Dense架构的推理速度不如MoE,但Claude通过优化模型效率,在保证稳定性的前提下,也能满足大多数场景的需求——比如Haiku版本,就是为低延迟场景优化的Dense模型,兼顾了速度和稳定性。
选型启示:为什么有的用MoE,有的用Dense?
从这三款工具的架构选择,我们能清晰地看到一个规律:架构选择,本质是“产品定位与技术特性的匹配”。
-
如果产品主打“高速度、高吞吐、专业化任务”(比如代码生成、实时响应),优先选MoE架构——Codex和Cursor的选择,都是基于这个逻辑;
-
如果产品主打“稳定性、长上下文、深度推理”(比如长文档分析、复杂逻辑推理),优先选Dense架构——Claude的全系列选择,正是为了契合这一定位。
这也给我们一个启示:无论是选择AI工具,还是自己做模型架构设计,都不要盲目追求“MoE比Dense高级”,而是要结合实际需求——没有最好的架构,只有最适合的架构。
最后总结
MoE是“专业化分工的高效选手”,适合追求速度和低成本、场景单一且明确的需求;Dense是“全能稳定的实力派”,适合追求稳定性、连贯性和深度推理的需求。
而Codex、Cursor、Claude的架构选择,正是这一逻辑的完美体现:
-
Codex(MoE):快准狠,适配代码生成的实时需求;
-
Cursor Composer(MoE):低延迟,适配IDE场景的无缝衔接;
-
Claude(Dense):稳准全,适配长文档和深度推理。